Пошукова система Google впроваджує інструменти для глибшого розуміння сенсу запитів, використовуючи векторні представлення тексту для визначення семантичної схожості.
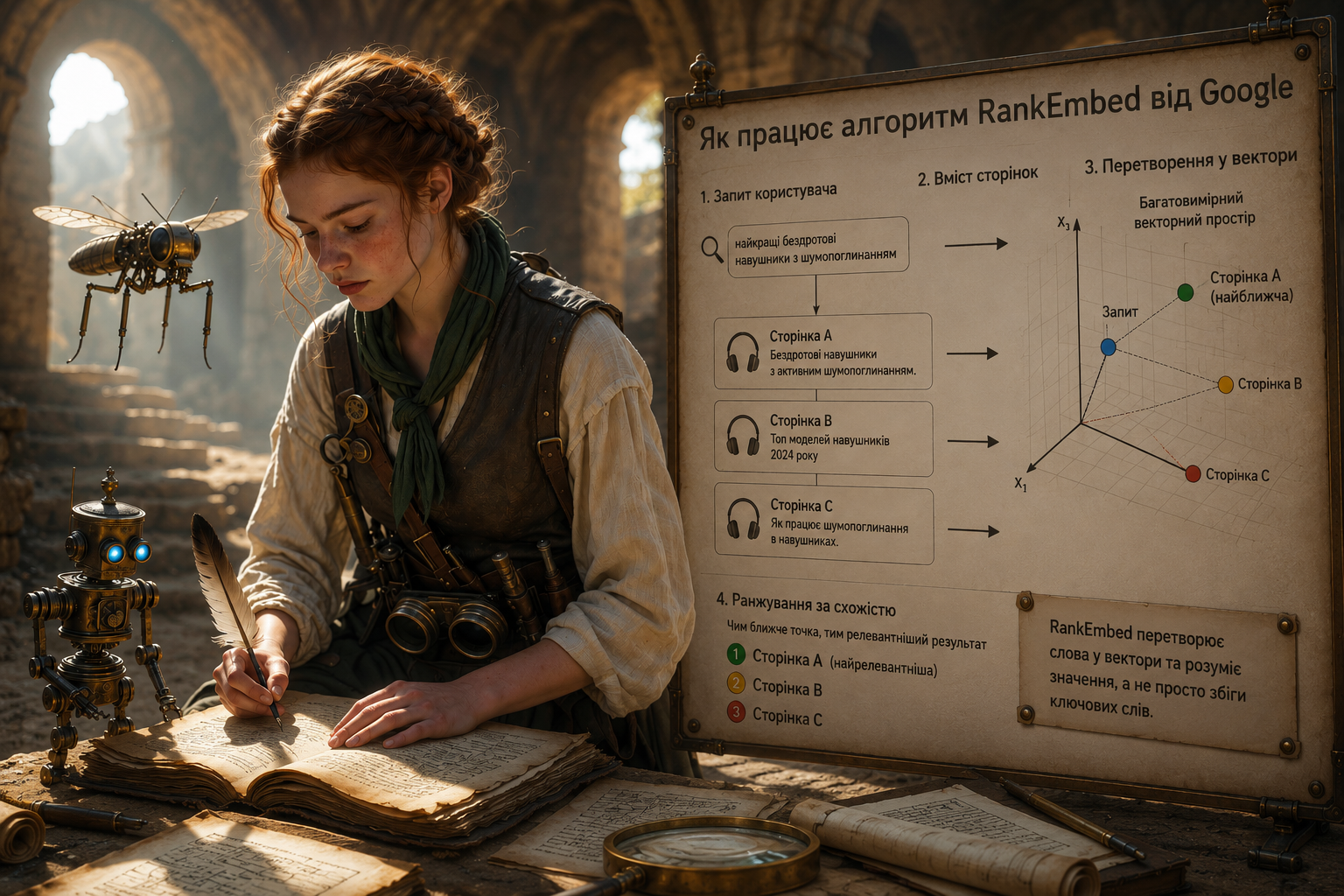
Чи може пошуковик зрозуміти, що сторінка про «стратега цифрового зростання» є релевантною відповіддю на запит «найкращий SEO-консультант», навіть якщо ці конкретні слова не перетинаються? Для розв’язання таких завдань Google використовує модель RankEmbed. Цей алгоритм глибокого навчання перетворює текст на багатовимірні числові значення, що дозволяє системі порівнювати сенси, а не просто зіставляти літери.
Основні тези
• Чи може пошуковик зрозуміти, що сторінка про «стратега цифрового зростання» є релевантною відповіддю на запит «найкращий SEO-консультант», навіть якщо ці конкретні слова не перетинаються?
• RankEmbed працює як один із багатьох сигналів у складній багаторівневій системі ранжування Google.
• Поки традиційний пошук часто спирається на принцип інвертованого індексу, шукаючи сторінки з конкретними словами, RankEmbed перетворює запит користувача та вміст сторінки у вектори.
Технологічний фундамент
RankEmbed працює як один із багатьох сигналів у складній багаторівневій системі ранжування Google. Він не замінює традиційний пошук за ключовими словами, а доповнює його, допомагаючи системі краще розуміти семантичну близькість, особливо коли йдеться про довгі та специфічні запити (так звані long-tail queries).
Поки традиційний пошук часто спирається на принцип інвертованого індексу, шукаючи сторінки з конкретними словами, RankEmbed перетворює запит користувача та вміст сторінки у вектори. Уявіть це як точки в багатовимірному просторі: якщо дві точки розташовані близько одна до одної, це означає, що вони мають схоже значення, незалежно від того, які саме слова були використані.
Для того щоб точно виміряти цю відстань, Google застосовує математичний метод косинусної подібності. Якщо результат розрахунку наближається до одиниці, система вважає сторінку максимально релевантною за змістом. Саме косинусна подібність дозволяє пошуковику ефективно обробляти розмовні запити, де користувач може не знати точних термінів, але чітко формулює свій інтент.
Більше контексту зі справи антимонопольного суду проти Google.
“RankEmbed — це модель подвійного кодувальника, яка вбудовує як запит, так і документ у простір вбудовування. Простір вбудовування враховує семантичні властивості запиту та документа на додаток до інших сигналів. Пошук і ранжування потім є скалярним добутком (мірою відстані в просторі вбудовування). Надзвичайно швидкий; висока якість для поширених запитів, але може працювати погано для запитів з довгим хвостом.”, — це цитата з “Офіційних матеріалів свідчень глави пошуку Панду Наяка.”
Google розробив систему глибокого навчання RankEmbed, щоб краще шукати та ранжувати документи. Це один із головних сигналів пошуковика, який тренували на базі великих мовних моделей. Система перетворює запити та сторінки у вектори (ембеддинги) і порівнює їх у багатовимірному семантичному просторі. Якщо запит і документ розташовані близько один до одного, алгоритм вважає їх спорідненими за змістом. Такий підхід працює швидко й ефективно, навіть якщо в самому запиті немає точних слів зі статті. Особливо добре RankEmbed допомагає з «довгохвостими» запитами, де розуміння контексту мови важливіше за простий підрахунок ключів.
Для навчання моделі використовували дані про кліки та реальні пошукові запити за один місяць. Також Google залучав оцінювачів (human raters), які перевіряли якість видачі, щоб «дотренувати» систему. Хоча RankEmbed BERT (розширена версія моделі) використовує менше даних, ніж традиційні системи підрахунку, він краще спирається на досвід користувачів, аналізуючи виділені терміни та відповідні сторінки.
Система чудово розуміє мову, проте гірше запам’ятовує конкретні факти. Її головна роль — заповнювати прогалини в даних про кліки, дозволяючи Google прогнозувати релевантність у нових ситуаціях. Цікаво, що RankEmbed може помилятися на дуже рідкісних запитах, хоча для популярних тем він показує високу якість. Через складність архітектури модель часто називають «чорним ящиком», адже розробникам важко точно пояснити механіку її внутрішніх рішень. Важливо розуміти, що це лише один із багатьох компонентів Google Search, а не вся пошукова система загалом.
RankEmbed та архітектура FastSearch
Згідно з документами антимонопольного процесу, модель RankEmbed є частиною архітектури Google FastSearch. Це окрема технологія, оптимізована для високої швидкості обробки даних. FastSearch використовує сигнали RankEmbed для швидкого формування відповідей, зокрема для роботи AI Overviews (штучного інтелекту в пошуковій видачі), де важливо забезпечити точне «заземлення» (grounding) відповідей Gemini на реальних даних.
Варто розуміти, що FastSearch не є повною заміною основного пошукового алгоритму, який обробляє стандартну видачу, а працює як спеціалізований інструмент для прискорення та уточнення семантичного пошуку.
Що це означає для SEO та створення контенту?
Поява таких моделей, як RankEmbed, часто інтерпретують як «смерть» традиційного SEO, проте це перебільшення. Внутрішні документи Google та думки експертів підтверджують: класичні сигнали, такі як якість посилань, швидкість завантаження сторінки та наявність ключових слів, залишаються важливими.
Проте акценти зміщуються. Тепер недостатньо просто повторити ключову фразу кілька разів. Для того щоб модель RankEmbed правильно визначила координати сторінки у векторному просторі, авторам варто зосередитися на тематичній глибині. Використання сутностей — конкретних назв компаній, галузевих термінів та відомих імен — допомагає системі точніше ідентифікувати тему тексту та його відповідність інтенту користувача.
Розвиток векторних представлень дозволяє усунути розрив між тим, як люди формулюють запити природною мовою, і тим, як інформація записана на сторінках. У довгостроковій перспективі це сприятиме домінуванню контенту, який надає вичерпні та експертні відповіді, охоплюючи тему повністю, а не лише формально оптимізуючи текст під окремі слова.
RankEmbed є ключовим елементом у еволюції пошукових алгоритмів Google, що відображає перехід до більшого використання машинного навчання та глибокого навчання для покращення розуміння запитів та релевантності результатів.